计算理论
自动机理论
正则语言
Concepts
- DFA: 确定型有穷自动机
- NFA: 非确定有穷自动机
- 正则语言:能被一个有穷自动机接受的语言就是正则语言
- 语言: 如果
A是机器M所接受的所有字符串组成的集合,那么我们就说A是 机器M的语言.也可以写作
L(M)=A 或者 M 识别 A.
DFA
Definition
有穷自动机是一个五元组 $(Q, \Sigma, \delta, q_0, F)$:
- Q 是一个有穷集合,叫 状态集.
- $\Sigma$ 是一个有穷集合,叫 字母表.
- $\delta: Q \times \Sigma \rightarrow Q$ 是 转移函数.
- $q_0 \in Q$ 是 起始状态.
- $F \subseteq Q$ 是 接受状态.
example
下面是一个叫 M1 的有穷自动机
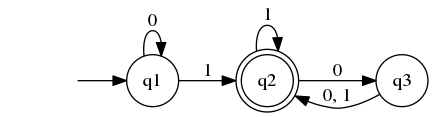
形式定义如下:
Q 是 {q1, q2, q3}
$\Sigma$ 是 {0, 1}
转移函数 $\delta$ 由下表给出:
0 1 q1 q1 q2 q2 q3 q2 q3 q2 q2 transformation rules
q1 是起始状态
F = |q2|
下面是一个M1的程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23(define (m1 ss)
(define tbl ;transformation rules
'(((q1 . #\0) . q1) ((q1 . #\1) . q2)
((q2 . #\0) . q3) ((q2 . #\1) . q2)
((q3 . #\0) . q2) ((q3 . #\1) . q2)))
(define accepted-states
'(q2))
(define m1-inner
(let ([state 'q1])
(lambda (input)
(cond [(assoc `(,state . ,input) tbl) =>
(lambda (entry)
(set! state (cdr entry))
(cdr entry))]
[else (error 'Error "unkown state input pair ~a"
`(,state ,input))]))))
(let* ([char-lst (string->list ss)]
[ret (last (map m1-inner char-lst))])
(if (memv ret accepted-states)
'accept
'reject)))设M = $(Q, \Sigma, \delta, q_0, F)$ 是一台有穷自动机, $\omega=\omega_1
\omega_2 … \omega_n$ 是字母表 $\Sigma$ 上的字符串,如果存在 Q 中的状态序列:
r0, r1, …, rn 满足下述条件:- r0 = q0
- $\delta(r_i, \omega_{i+1})=r_{i+1}, i=0,1,2,…,n-1$
- $r_n \in F$
则 M 接受 $\omega$.
正则运算
设 A 与 B 是两个语言, 定义正则运算 并 连接 星号:
- union(并) : $A \cup B = {x| x \in A \ or \ x \in B }$
- concatenation(连接):
$A \centerdot B = {xy| x \in A \ and \ y \in B }$ - star 星号:
$A^* = {x_1 x_2 x_3 … x_k| k \geq 0 \ and \ \forall x_i \in A}$
property
正则语言类是所有正则语言组成的集合
- 正则语言类在 并 运算下封闭 (closure under union)
- 正则语言类在 连接 运算下封闭(closure under concatenation)
正则表达式
- $(r)|(s)$ is a regular expression denoting the language $L(r) U L(s)$
- (r)(S) is a regular expression denoting the language $L(r)L(s)$
- $(r)$ is a regular expression denoting the language $L(r)^$
- $(r)$ is a regular expression denoting the language $L(r)$
some extensions:
- $(r)+$ is a regular expression denoting the language $L(r)+, r+ = rr*$.
- $(r)?$ (zero or one)
- $[abcd]$ is shorthand of $a|b|c|d$
NFA
DFA VS NFA
- DFA的每一个状态对于字母表中的每一个符号总是恰好有一个转移箭头射出,而NFA对
于每一个状态对于字母表字母表的每一个符号可能有0,1
或者多个箭头射出. - NFA中箭头的标号可以是 $\varepsilon$, 而DFA不允许.
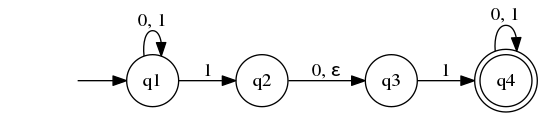
- DFA的每一个状态对于字母表中的每一个符号总是恰好有一个转移箭头射出,而NFA对
definition
非确定型有穷自动机是一个五元组 $(Q, \Sigma, \delta, q_0, F)$:
- Q 是一个有穷集合,叫 状态集.
- $\Sigma$ 是一个有穷集合,叫 字母表.
- $\delta: Q \times \Sigma_\varepsilon \rightarrow \mathcal{P}(Q)$
是 转移函数. - $q_0 \in Q$ 是 起始状态.
- $F \subseteq Q$ 是 接受状态.
DFN的直观理解
非确定性可以看做若干”过程”能同时运行的一类并行计算.当NFA分头跟踪若干选择
时,这对应于一个过程分叉成若干个子过程,各子过程分别进行.如果这些子过程中
至少有一个接受,那么整个计算接受把非确定性计算看作一颗可能性的树,树根对应计算的开始,树中的每一个分支点对
应计算中机器有多种选择的点.如果计算分支中至少有一个结束在接受状态,则机器
接受.该理解是这样操作的: 当读入字符串时,如果发现该字符串可以到达n个下一状态 那么该节点就会有 n个子节点.如果发现有
$\varepsilon$ 箭头,那么就直接分裂 出一个子节点.下图描述了 N1 对 010110的 计算
property
每一台 NFA 都有一台等价的 DFA与之对应
正则语言类在并运算下封闭
Proof: 假设有正则语言 A1 A2, 它们对应的 NFA为 N1 N2, 现在构造出一台NFA, 它能够识别出 A1 U
A2, 构造的方法就是使用一个新的初始状态q0, 而从 q0 上 分别连一个
$\varepsilon$ 箭头到N1 与 N2 的初始状态,见下图: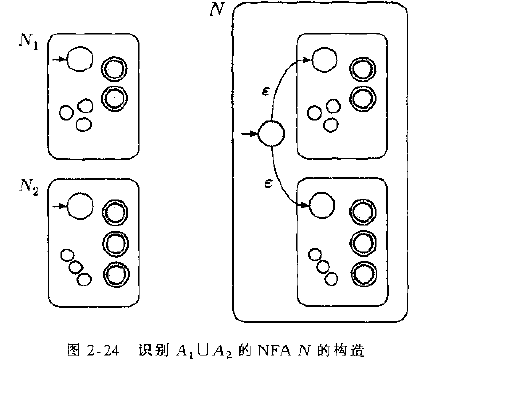
正则语言在连接运算下封闭
Proof: 假设有正则语言 A1 A2, 它们对应的 NFA为 N1 N2, 现在构造出一台NFA, 它能够识别出 A1
A2, 构造的方法就是从N1的每一个接受状态都连一个 $\varepsilon$ 箭头到N2
的初始状态,见下图:
正则语言类在星号运算下封闭

非正则语言
泵引理: 设A是一个正则语言,则存在一个数 p(泵长度)使得, 如果s是A中任一长度不小 于p的字符串, 那么s可以被分为3段,
s=xyz,满足下述条件:
- 对每一个 $i \geqslant 0, xy^iz \in A$
- |y| > 0
- |xy| <= p
上下文无关语言
definition
上下文无关文法是一个四元组 $(V, \Sigma, R, S)$, 这里:
- V 是一个有穷集合,称作 变元集.(箭头左边的部分)
- $\Sigma$ 是一个与 V 不想交的有穷集合,称作 终结符集.
- R 是一个有穷的规则集,每一条规则是一个变元和一个由变元与终结符组成的字符 串
- $S \in V$ 是 起始变元.
乔姆斯基范式
一个上下文无关文法为乔姆斯基范式,如果它的每一条规则具有如下的形式:
$A \rightarrow BC$ $A \rightarrow a$ a是任意的终结符,
A,B,c使任意的变元,但是B,C不能是起始变元.
可计算理论
计算复杂度理论
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!