SQL笔记
SQL基本知识与常用代码
conventions
- SQL 不区分大小写,但是惯例是SQL的关键字要大写, 所有的列名,表名,数据库名都 用小写.
- 每一条SQL语句后加分号;
- SQL不区分空格,所以为了可读性,可以把Sql语句分成多行.
登录
1 | |
增加新用户
grant 权限 on 数据库.* to 用户名称@登陆主机 identified 密码
1
2
3grant select, insert, update, delete
on books.*
to user identified by '1234'
database相关
- create database 数据库名; (创建数据库)
- show databases; (显示所有数据库)
- use dbname; (改变当前数据库)
SHOW
- SHOW DATABASES;
- SHOW TABLES;
- SHOW COLUMNS FROM tbname; (显示数据表tbname的结构)
- DESCRIBE tbname; (等价于 show columns from tbname;)
- SHOW STATUS; (显示数据库的基本信息)
- SHOW GRANTS [username]; (显示当前用户或username的权限)
- SHOW CREATE DATABASE dbname; (显示创建数据库dbname的sql语句)
- SHOW CREATE DATABASE tbname; (显示创建数据表tbname的sql语句)
SELECT
select用来检索数据, 检索时至少要指定两条信息:
你要检索什么(field name)
从哪里检索(database name)
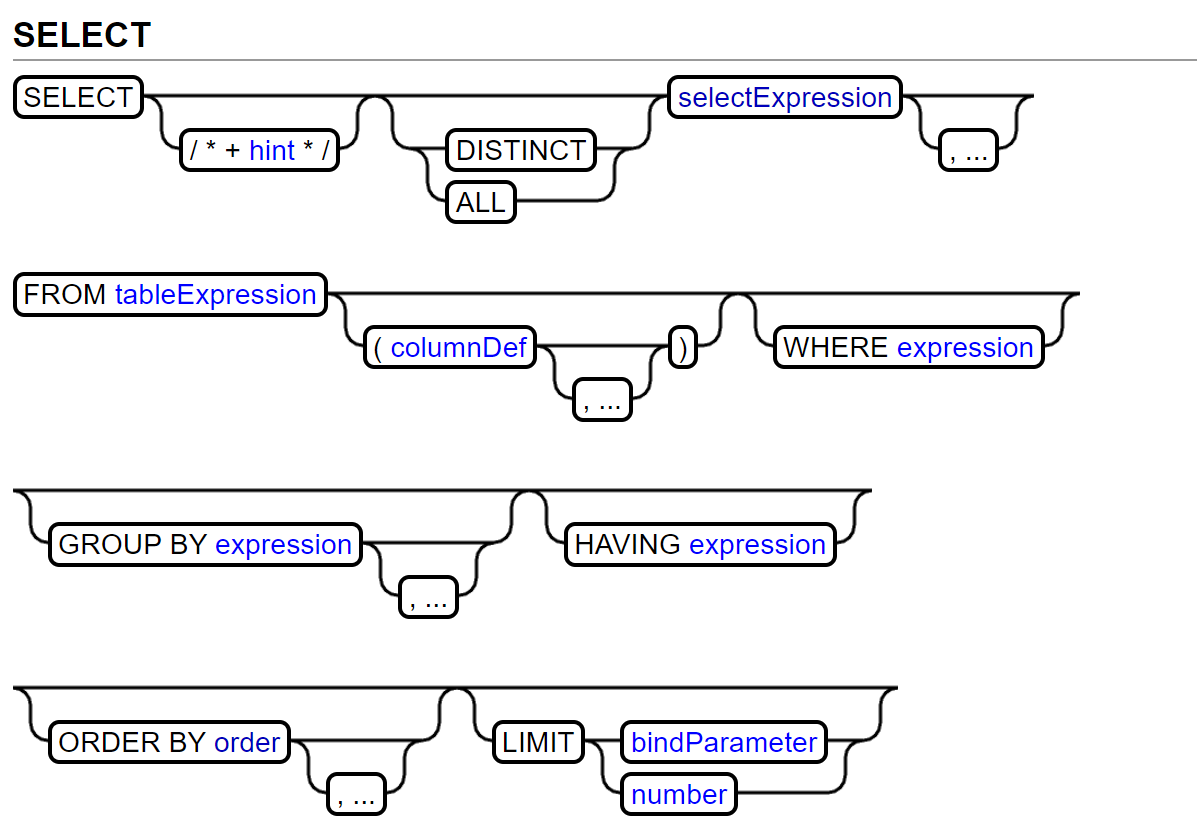
1
2
3
4
5
6
7
8
9
10
11
12
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s)
LIMIT N;
SELECT 列1,列2 FROM 表名
SELECT 表1.列1, 表2. 列2 FROM 表1, 表2(多张表中选取)
SELECT * FROM 表名
SELECT DISTINCT 列2 FROM 表名 (去除重复)
注意事项:
- WHERE的表达式不能有aggregate function
- 为了弥补WHERE的不足所以有HAVING子句,HAVING的表达式可以有aggregate function.
- ORDER BY的表达式也可以包含aggregate functions
- ORDER BY以及HAVING中的aggregate functions都不是必须出现在select的column_name中
同时还可以指定一些过滤规则与排序规则, 这一般是通过子句实现的:
- ORDER BY 列1, 列2 [DESC|ASC] : 必须在where子句后,在limit子句前.
- LIMIT num : 用来指定最多返回多少条记录.必须在order by子句之后.
- WHERE 子句: 指定过滤条件(尽量在数据库层面过滤数据,而不要在语言层面(如 php,python)过滤数据),
因为数据库过滤效率较高, 而且也可以避免不必要的数据 在数据库服务端到数据库客户端的传输WHERE 列名 操作符 值
对应的列如果是整数那么值就不要引号,如果是字符串那么值就加单引号.
操作符有:
operator meaning ,>,>,<,<=, <>, !=等于,大于..etc(!=, <>都是不等于的意思) BETWEEN 介于指定值之间 IN 枚举(可以看做是OR的简写) NOT MySQL只允许NOT出现在IN, BETWEEN, EXISTS之前, 也就是NOT IN, NOT BETWEEN, NOT EXISTS LIKE 使用通配符来匹配字段,性能不是很高,所以慎用 REGEX 使用正则表达式来匹配字段,性能也不是很高,所以慎用 LIKE: 模式必须匹配整个列,而不是一列的一部分
- %: 代表任意字符出现任意次数
- _: 代表单个字符
通配符要尽量少用,特别是不要放在模式的开头,因为那非常慢.
1
2
3SELECT prod_name, prod_price
FROM products
WHERE prod_name LIKE '%anvil%';REGEX: 和一般的正则表达式差不多
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22-- (greater than)
SELECT prod_name, prod_price
FROM products
WHERE prod_price > 10;
-- (not equal)
SELECT vend_id, prod_name
FROM products
WHERE vend_id != 1003;
-- (between)
SELECT prod_name, prod_price
FROM products
WHERE prod_price BETWEEN 5 AND 10;
-- (in)
SELECT prod_name, prod_price
FROM products
WHERE vend_id IN (1002, 1003)
ORDER BY prod_name;
-- NOT IN
SELECT prod_name, prod_price
FROM products
WHERE vend_id NOT IN (1002, 1003)
ORDER BY prod_name;逻辑联结词 AND, OR
可以用来连接多个过滤条件,必要时要加小括号来分组.
1
2
3
4
5
6
7SELECT prod_name, prod_price
FROM products
WHERE vend_id = 1003 AND prod_price < 10;
-- OR
SELECT prod_name, prod_price
FROM products
WHERE vend_id = 1001 OR vend_id = 1002;创建计算字段:
假设一个订单表包含一个price字段以及一个quantity字段, 那么为了计算总价,就 可以用下面的语句
1
2
3
4SELECT price,
quantity,
price*quantity AS expanded_price
FROM orderitems那么上面的
expanded_price字段并不存在于数据表中, 而是根据已有字段 计算出来的, 对于数字字段可以使用
+,-,*,/. 对于字符串字段可以使用 拼 接 (MySQL用Concat, 其它数据库一般用 ||或+),
删除空格(RTrim, LTrim, Trim).1
2
3
4SELECT Concat(RTrim(vend_name), '(', RTrim(vend_country), ')') AS
vend_title
FROM vendors
ORDER BY vend_name;函数
字符串函数(Upper, Lower, LTrim, RTrim, Trim, Substring …)
日期,时间函数(Now, Curdate, Curtime, Year, Month, Day…)
日期的格式应该是: yyyy-mm-dd
1
2
3
4
5
6
7
8
9
10
11SELECT cust_id, order_num
FROM orders
WHERE Date(order_date) = '2005-09-01';
-- orders in 2005-09
SELECT cust_id, order_num
FROM orders
WHERE Date(order_date) BETWEEN '2005-09-01' AND '2005-9-30';
-- identical(better version)
SELECT cust_id, order_num
FROM orders
WHERE Year(order_date) = 2005 AND Month(order_date) = 9;数值处理函数: Abs, Sin, Cos 等等
聚集函数: AVG, COUNT, MAX, MIN, SUM.
1
2
3
4
5SELECT COUNT(*) AS num_items,
MIN(prod_price) AS price_min,
MAX(prod_price) AS price_max,
AVG(prod_price) AS price_avg
FROM products;结果类似于:
1
2
3
4
5+-----------+-----------+-----------+-----------+
| num_items | price_min | price_max | price_avg |
|-----------+-----------+-----------+-----------|
| 14 | 2.50 | 55.00 | 16.133571 |
+-----------+-----------+-----------+-----------+
联接
内联接(等值联接)
vendors表存储制造商信息,其主键为vend_id, products表存储产品信息,其中有一个 外键
vend_id指向vendors表.
1 | |
上例可以这样理解,先使用下面这两条语句:
1 | |
进行检索, 然后把二者的结果集进行自由组合(笛卡尔积), 紧接着将这些结果中 vendors.vend_id <> products.vend_id 的结果剔除掉.
等价的形式是:
1 | |
INNER JOIN 是推荐的写法.
自联接
联接的两个表是同一个表
1 | |
子查询
一个select 返回的结果作为另外一条select 的条件.
1 | |
子查询常用的场景有两个: 通过 WHERE IN
UNION
- 必须是两条或者两条以上select语句
- 每个select语句必须包含相同的列,表达式或者汇集函数.
- 列数据类型必须兼容
1 | |
INSERT(增)
插入一条记录,省略列名:
1
INSERT INTO 表名 VALUES(val1, val2 ...)插入一条记录:
1
INSERT INTO 表名 (列1,列2 ...) VALUES (val1, val2 ...)插入多条记录:
1
INSERT INTO 表名 (列1,列2 ...) VALUES (val1, val2 ...), (val1, val2 ...)
DELETE(删)
- delete from 表名称 where 列名称=值
- delete from 表名称 (删除所有行,但是保留表)
- delete * from 表名称 (删除所有行,但是保留表)
- truncate table 表名 (删除所有行,效率更高)
UPDATE(改)
更新数据表某一列或者多列(特别要注意where子句)
1 | |
CREATE TABLE
创建表,基本语法:
1 | |
尽量指定NULL或者NOT NULL, 一般约束是可选的
数据类型
字符串类型
CHAR 1~255个字符长度的定长字符串,长度必须创建时指定 ENUM 枚举,值只能是预定义集合中的某一个 LONGTEXT MEDIUMTEXT SET 预定义集合中的0个或者多个串 TEXT 最长 64k 的变长字符串 TINYTEXT VARCHAR 长度可变,最长不超过255个字节 用的较多的就是: CHAR, VARCHAR, TEXT. 在sql语句中对于字符串值要用引号.
数值类型(如果确定为非负数,可以在类型前加 UNSIGNED)
BIT 位字段, 1~64位 BIGINT BOOLEAN(或BOOL) 布尔(0或者1) DECIMAL(或DEC) 精度可变的浮点 DOUBLE 双精度浮点 FLOAT 单精度浮点 INT(或INTEGER) 整数 MEDIUMINT REAL SMALLINT 用的较多的就是: INT, BOOLEAN, DOUBLE, FLOAT. 在sql中数值类型不要加引号.
时间日期类型
DATE 日期,格式为: YYYY-MM-DD TIME 格式为: HH:MM:SS DATETIME DATE和TIME的组合 TIMESTAMP 功能和DATETIME相同,但范围较小 YEAR 年份,2位数字则范围是: 1970~2069, 4为数字则范围:1901~2155 用的较多的是 DATETIME, DATE, TIME这三个类型.
二进制类型
BLOB 64kb MEDIUMBLOB 16mb LONGBLOB 4GB TINYBLOB 255个字节 用的较多的就是: BLOB
约束
- NOT NULL: 应该紧挨着类型的后面.
- PRIMARY KEY:主键,不用再指定unique。
- UNIQUE:字段必须唯一, 但是字段可以为NULL. 也就是说UNIQUE不会检查 NULL值.可
以指定多个字段,也就是说规定指定字段的组合必须唯一. - FOREIGN KEY:外键
- CHECK:值范围,eg:check(Id>0).
- DEFAULT: 默认值,default ‘yangyu’, MySQL不接受函数作为默认值.
- AUTO_INCREMENT:通常对主键。
INDEX(索引)
- 创建索引:CREATE INDEX indexname ON tablename (column [ASC|DESC], …);
- 删除索引:DROP INDEX indexname ON tablename;
DROP
- 删除表 : drop table 表名
- 删除数据库: drop database 数据库名
1 | |
ALTER(修改表结构)
1 | |
增加列: alert table 表名 add 列名 数据类型
1
2ALTER TABLE vendors
ADD vend_phone CHAR(20);删除列: ALTER TABLE 表名 DROP column 列名
1
2ALTER TABLE vendors
DROP COLUMN vend_phone;修改列: ALTER TABLE 表名 CHANGE COLUMN 列名 数据类型
定义外键:
1
2
3ALTER TABLE products
ADD CONSTRAINT fk_products_vendors
FOREIGN KEY(vend_id) REFERENCES vendors(vend_id);从products.vend_id 到 vendors.vend_id的外键.
存储过程(MySQL 5.1)
可以看做是SQl语言中的自定义函数. 也就是把一系列的 SQL 语句打包成一个自定义函 数,然后通过这个函数名来调用这一系列的SQL语句.
1 | |
IN 代表输入参数, OUT代表输出参数.
调用存储过程(参数要以 @ 开头):
1 | |
事务(transaction)
MySQL的 MySAIM 存储引擎不支持事务, InnoDB 支持事务, MySQL5.5的默认引擎是 InnoDB.
为了保证数据库数据在逻辑上的一致性,有一些操作应该打包执行,也就是说这些SQL语
句要么全部执行成功,要么一条都不执行,不能出现一部分执行成功,而另外一部分执行
失败的情况.
1 | |
在 START TRANSACTION 与 COMMIT 之间的 SQL 语句被打包成一个事务.
从文件创建数据表
- mysql –u -p root < file.sql
数据库设计的三大范式:
- 第一范式:字段不可分,
- 第二范式:有主键,非主键字段要依赖主键字段只要数据列里面的内容出现重复,就 意味着应该将表拆分,拆分形成的表必须用外键关联起来。
- 第三范式:非主键字段不能相互依赖,也就是说表中的每一列必须与主键直接相关而
不能间接相关。与主键没有直接关系的数据列必须清除(创建一个表来存放他们)。
数据库的常用模式
主扩展模式
比如说公司有不同类型的员工,如设计师,程序员,PM等,那么可以先建一个员工表,
这个表存放所有类型的员工都有的属性,如姓名,性别,入职时间等等等,然后在设计
师一个表,程序员一个表,PM一个表,但是这些表都与员工表关联
主从模式
一张表的一条记录对应另一张表的多条记录。也就是一对多 eg:论坛的板块表与帖子表就是这种关系,而帖子表与回复表也是这种关系
名值模式
多对多模式
一本书可以有多个作者,一个作者也可以写多本书,所以书目信息表与作者信息表就是
多对多关系,那么设计时通常是在加入一个关联表,也就是通过3个表来表示这种关系
一些建议
- LIKE 很慢, 所以一般情况下,最好使用 full text.
- 绝不要检索比需求多的数据, 所以不要使用 SELECT * 这样的语句.
- 如果where中有很多的 OR 条件, 那么使用 UNION将其分拆为多条 select 语句会看 到明显的性能改善.
- 在插入数据频繁的场景下, 应该删除外键, 在应用层面检查约束就可以了, 因为插入 频繁时,外键会明显降低性能.
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!